I presented on building trust in algorithms and providing users control over them at the 4th Human Factors Engineering and Usability Studies Congress. You can download my original slides here.
 Hi everyone, good afternoon. What a couple of days, huh? Thanks for sticking around long enough to listen to me. Let’s talk trust in algorithms, and what we can do to keep people comfortable. I’m calling this one — It Came From the Black Box!
Hi everyone, good afternoon. What a couple of days, huh? Thanks for sticking around long enough to listen to me. Let’s talk trust in algorithms, and what we can do to keep people comfortable. I’m calling this one — It Came From the Black Box!
 If there’s one thing I want to leave you with today, it’s this: don’t be Aleister Crowley.
If there’s one thing I want to leave you with today, it’s this: don’t be Aleister Crowley.
 Aleister Crowely was born in 1875 and pretty quickly decided that everything about his life had to change. He rebelled against his parents, the institutions around him, and especially his religion. His mother called him “a beast,” a moniker he adopted to become the self-styled Great Beast 666.
Aleister Crowely was born in 1875 and pretty quickly decided that everything about his life had to change. He rebelled against his parents, the institutions around him, and especially his religion. His mother called him “a beast,” a moniker he adopted to become the self-styled Great Beast 666.
 But eveyone else called him The Wickedest Man in the World. He created the religion of Thelema that had one law: “DO WHAT THOU WILT.” He bent people to his will, breaking apart marriages so he could sleep with whatever woman he wanted — whether they wanted it or not.
But eveyone else called him The Wickedest Man in the World. He created the religion of Thelema that had one law: “DO WHAT THOU WILT.” He bent people to his will, breaking apart marriages so he could sleep with whatever woman he wanted — whether they wanted it or not.
 When mountaineering, he — that’s him second from left — and his climbing group were trapped in a storm. Crowley left them to die — the rumor is that he was drinking tea while they begged him for help that he refused to provide.
When mountaineering, he — that’s him second from left — and his climbing group were trapped in a storm. Crowley left them to die — the rumor is that he was drinking tea while they begged him for help that he refused to provide.
 One of his followers drank cat’s blood. Her husband later died when he drank from polluted water — either because he was forced to or because it was all he had access to. Many of the stories about crowley were probably overblown — it’s unlikely he sacrificed children —
One of his followers drank cat’s blood. Her husband later died when he drank from polluted water — either because he was forced to or because it was all he had access to. Many of the stories about crowley were probably overblown — it’s unlikely he sacrificed children —
 But the crux of it is Crowley’s embrace and usage of the occult were what gave him his power.
But the crux of it is Crowley’s embrace and usage of the occult were what gave him his power.
 Not in like, a magic way, though. What’s so insidious about “the occult” can be found in the meaning of the word itself —
Not in like, a magic way, though. What’s so insidious about “the occult” can be found in the meaning of the word itself —
 — it’s hidden. If you have an occult diagnosis at the doctor’s office, it’s something that doesn’t have a lot of signs or symptoms.
— it’s hidden. If you have an occult diagnosis at the doctor’s office, it’s something that doesn’t have a lot of signs or symptoms.
 Crowley was so dangerous because he was the only one who could interpret the meaning of the hidden supernatural — his followers had to trust him completely with no proof. That leads to situations that are rife for abuse. It leads to situations where people are making decisions based on nothing more than what they believe about a system, not what’s true about it. It leads to situations where you drink cat’s blood, simply because this strange, demon-obsessed man told you to.
Crowley was so dangerous because he was the only one who could interpret the meaning of the hidden supernatural — his followers had to trust him completely with no proof. That leads to situations that are rife for abuse. It leads to situations where people are making decisions based on nothing more than what they believe about a system, not what’s true about it. It leads to situations where you drink cat’s blood, simply because this strange, demon-obsessed man told you to.
 If your users ever get into a situation where they say, “I don’t know how it works, I just keep using it” — congratulations, you have entered the realm of the occult. Prepare for a sacrifice, either in the form of a life or a lawsuit.
If your users ever get into a situation where they say, “I don’t know how it works, I just keep using it” — congratulations, you have entered the realm of the occult. Prepare for a sacrifice, either in the form of a life or a lawsuit.
 Trust without knowledge is faith. And while faith is a fine thing, we don’t build medical devices based on it.
Trust without knowledge is faith. And while faith is a fine thing, we don’t build medical devices based on it.
 The opposite of the occult — what reveals hidden things — is information and understanding. Our job as designers is to provide our users the knowledge they need to understand how an algorithm works. Even if they’re not working with it directly, it is impacting the patient, and thus is their responsibility. I’m really passionate about this, so let me tell you a little about who I am and why I’m here today.
The opposite of the occult — what reveals hidden things — is information and understanding. Our job as designers is to provide our users the knowledge they need to understand how an algorithm works. Even if they’re not working with it directly, it is impacting the patient, and thus is their responsibility. I’m really passionate about this, so let me tell you a little about who I am and why I’m here today.
 So — hellooooo. My name is Andrew Lilja, and I’m a principal human factors design engineer at Medtronic. I work in the Cardiac Rhythm Group, which means it’s my job to build things that keep people alive when their hearts don’t want to anymore. We do this in a whole bunch of ways, but I’m mostly responsible for the devices that put a bunch of electricty into people.
So — hellooooo. My name is Andrew Lilja, and I’m a principal human factors design engineer at Medtronic. I work in the Cardiac Rhythm Group, which means it’s my job to build things that keep people alive when their hearts don’t want to anymore. We do this in a whole bunch of ways, but I’m mostly responsible for the devices that put a bunch of electricty into people.
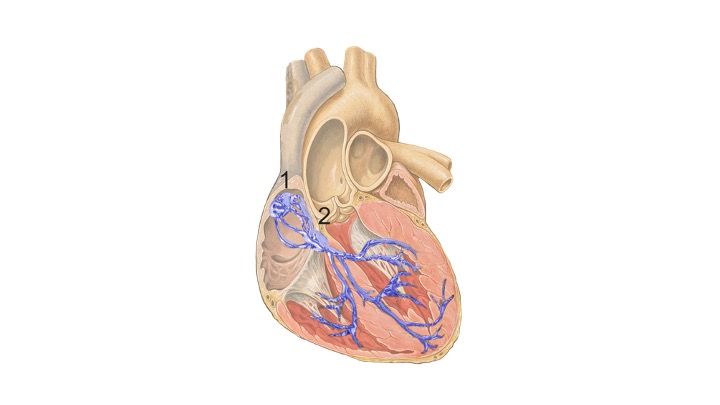 This might come as a surprise, but hearts are actually very good at beating.
This might come as a surprise, but hearts are actually very good at beating.
 You have a little part of it right here
You have a little part of it right here
 Called the sinoatrial node that helps organize electrical signals from the brain and turn them into heartbeats. It’s so good at this that you can actually remove a heart from the body completely and it will still beat on its own at a steady 60 beats per second. But sometimes things go wrong. There might be physiological issues with the nerves or the muscles, or there might be something wrong with the connection between the brain and the heart.
Called the sinoatrial node that helps organize electrical signals from the brain and turn them into heartbeats. It’s so good at this that you can actually remove a heart from the body completely and it will still beat on its own at a steady 60 beats per second. But sometimes things go wrong. There might be physiological issues with the nerves or the muscles, or there might be something wrong with the connection between the brain and the heart.
 You can use a little jolt of electricity to make the heart beat again. If you do it at a steady rate, people can stand up and walk around and be alive again. And this works really great for about five minutes. Then the patient needs to run, or their heart starts beating on its own again, or their heart decides to really throw us for a loop and go into a fatal arrhythmia. These are things our basic pacemaker needs to expect and interpret, and we use a lot of algorithms to do that.
You can use a little jolt of electricity to make the heart beat again. If you do it at a steady rate, people can stand up and walk around and be alive again. And this works really great for about five minutes. Then the patient needs to run, or their heart starts beating on its own again, or their heart decides to really throw us for a loop and go into a fatal arrhythmia. These are things our basic pacemaker needs to expect and interpret, and we use a lot of algorithms to do that.
 But — let’s take a second to get our terminology straight. There is a lot of talk these days about “artificial intelligence.”
This so-called AI definitely relates to algorithms and what we work with, but let’s get clear about what all these things are. Personally, I hate the term AI.
But — let’s take a second to get our terminology straight. There is a lot of talk these days about “artificial intelligence.”
This so-called AI definitely relates to algorithms and what we work with, but let’s get clear about what all these things are. Personally, I hate the term AI.
 It’s so generic and general that it’s practically useless to discuss with.
It’s so generic and general that it’s practically useless to discuss with.
 What most people are thinking about when they say “AI” is what’s called a “large language model,” which at their very core are statistical models that have been given enough data so they can make good guesses about what words or pixels belong next to each other.
What most people are thinking about when they say “AI” is what’s called a “large language model,” which at their very core are statistical models that have been given enough data so they can make good guesses about what words or pixels belong next to each other.
 You feed it a bunch of images that have been tagged with things like “cat” and “box” and “very adorable,” and then when you give it the words “draw me an adorable cat” it can spit one out for you. The more pictures you gave it during “training” and the better your descriptions of them were, the more options you have down the line.
You feed it a bunch of images that have been tagged with things like “cat” and “box” and “very adorable,” and then when you give it the words “draw me an adorable cat” it can spit one out for you. The more pictures you gave it during “training” and the better your descriptions of them were, the more options you have down the line.
 LLMs are a a subgroup of a field called “machine learning,” which is exactly what it sounds like. All of them are basically black boxes. You understand the model — how they were built — but you have no insight into why it’s making the decisions it did. They’re just a huge network of statistical weights — there aren’t any rules that you can look at and understand.
LLMs are a a subgroup of a field called “machine learning,” which is exactly what it sounds like. All of them are basically black boxes. You understand the model — how they were built — but you have no insight into why it’s making the decisions it did. They’re just a huge network of statistical weights — there aren’t any rules that you can look at and understand.
 Compare this to an algorithm, which is a set of explicit, described rules that produce predictable outcomes. That’s the major difference: you can predict the precise outcome of an algorithm because you wrote the rules to make it work. Given the same input, you can predict what the output will be. If you get an incorrect or weird output, you can go to the algorithm and figure out what happened and fix it.
Compare this to an algorithm, which is a set of explicit, described rules that produce predictable outcomes. That’s the major difference: you can predict the precise outcome of an algorithm because you wrote the rules to make it work. Given the same input, you can predict what the output will be. If you get an incorrect or weird output, you can go to the algorithm and figure out what happened and fix it.
 An LLM — and ML generally — can create surprises. If it does something you didn’t expect, you can’t figure out why. All you know is that the group of inputs you gave it turned into that outputs. Maybe your training data was polluted. Naybe your input was bad. You don’t know! You can make some guesses, but you don’t know why.
An LLM — and ML generally — can create surprises. If it does something you didn’t expect, you can’t figure out why. All you know is that the group of inputs you gave it turned into that outputs. Maybe your training data was polluted. Naybe your input was bad. You don’t know! You can make some guesses, but you don’t know why.
 It’s an occult technology. You just have to trust that what goes in is going to give the correct output. And sometimes that’s what you want! If you want something that’s novel and entertaining, an LLM may be just what you’re looking for. But if you’re using this occult AI black box to determine when a patient needs a pacemaker beat, or to develop care plans, or do anything at all that could result in harm — don’t do it. Use an algorithm instead.
It’s an occult technology. You just have to trust that what goes in is going to give the correct output. And sometimes that’s what you want! If you want something that’s novel and entertaining, an LLM may be just what you’re looking for. But if you’re using this occult AI black box to determine when a patient needs a pacemaker beat, or to develop care plans, or do anything at all that could result in harm — don’t do it. Use an algorithm instead.
 The crux is that one is unknowable, and the other is not. And if your users know how it works, they can trust how it works. You want your users to know. You want them to be able to make predictions about outcomes. When they understand how it works, they can use it in their work. When it stops being mysterious and confusing, it starts to become usable.
The crux is that one is unknowable, and the other is not. And if your users know how it works, they can trust how it works. You want your users to know. You want them to be able to make predictions about outcomes. When they understand how it works, they can use it in their work. When it stops being mysterious and confusing, it starts to become usable.
 Things that are unknown are scary. You don’t know what’s happening, why the algorithm is doing something, how it can be controlled or managed or used.
Things that are unknown are scary. You don’t know what’s happening, why the algorithm is doing something, how it can be controlled or managed or used.
 But the minute your turn the lights of understanding on, you get it. Its purpose becomes understood and you can figure out how to leverage it. It might even become as boring as an office hallway. It stops being occult and starts being understandable.
But the minute your turn the lights of understanding on, you get it. Its purpose becomes understood and you can figure out how to leverage it. It might even become as boring as an office hallway. It stops being occult and starts being understandable.
 So if the opposite of the occult is the known, the visible — how do you do that? How do you build trust in something? I think there are two main ways we do it.
So if the opposite of the occult is the known, the visible — how do you do that? How do you build trust in something? I think there are two main ways we do it.
 Via feedback, and revealing the right complexities. Your job is to use those to make sure your users understand how the algorithm works, and how they can use it in their workflows.
Via feedback, and revealing the right complexities. Your job is to use those to make sure your users understand how the algorithm works, and how they can use it in their workflows.
 Let’s talk feedback first, because i think it’s simpler. Feedback is so fundamental to interfaces that Don Norman literally defined it.
Let’s talk feedback first, because i think it’s simpler. Feedback is so fundamental to interfaces that Don Norman literally defined it.
 (Pause for reading.) I want to take this one step further and add that it’s not just letting you know that the system is working on your request, it’s also telling you what the system is doing with your request. It’s saving, it’s searching, whatever.
(Pause for reading.) I want to take this one step further and add that it’s not just letting you know that the system is working on your request, it’s also telling you what the system is doing with your request. It’s saving, it’s searching, whatever.
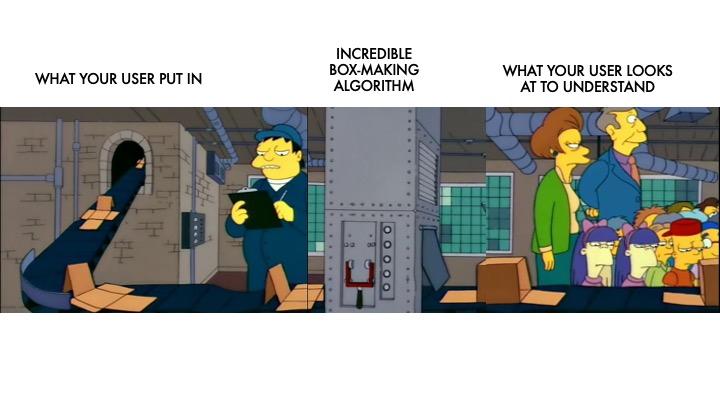 When it comes to an algorithm, this is about predictability. You put something into the algorithm and it comes out giving you an answer you expected — or at least within the range of spaces that you expected it to come from. You need to show your user what’s going on, how those inputs are being interpreted.
When it comes to an algorithm, this is about predictability. You put something into the algorithm and it comes out giving you an answer you expected — or at least within the range of spaces that you expected it to come from. You need to show your user what’s going on, how those inputs are being interpreted.
Your user sees flat paper going in, something happens, and then a box comes out — every single time. They use that feedback to build a mental model of what’s going on inside the algorithm. It lets them leverage the algorithm more effectively, too. When they see what comes out, they can learn how to put better things into it so they can get better outputs. You need to do this in your interfaces! You need to reveal what the output is.
 You know, one of the things we do as designers and researchers is define a “problem space” — given all the constraints and stakeholders and inputs to a problem, here’s the things the problem could be. The problem we’ll solve comes from this space.
You know, one of the things we do as designers and researchers is define a “problem space” — given all the constraints and stakeholders and inputs to a problem, here’s the things the problem could be. The problem we’ll solve comes from this space.
 I’d like you think of the reverse: and algorithmic “answer space” — given the inputs and all the rules of the algorithm, you know what a likely outcome from the algorithm is going to be. In their heads, your users will be developing this all the time. Every time they get an output back out, it will further define this answer space.
I’d like you think of the reverse: and algorithmic “answer space” — given the inputs and all the rules of the algorithm, you know what a likely outcome from the algorithm is going to be. In their heads, your users will be developing this all the time. Every time they get an output back out, it will further define this answer space.
 I’ll spare you from the details right now, but what’s happening is that your users are developing mental models of how the algorithm works, and you simply cannot stop them from doing that. Our brains will do it with just about anything. We are pattern-finding machines, which is why you look at this picture and see a face and not a pile of vegetables. Your users will grab onto any scrap of feedback they get from the algorithm and use it to make decisions about whether or not they can rely on it.
I’ll spare you from the details right now, but what’s happening is that your users are developing mental models of how the algorithm works, and you simply cannot stop them from doing that. Our brains will do it with just about anything. We are pattern-finding machines, which is why you look at this picture and see a face and not a pile of vegetables. Your users will grab onto any scrap of feedback they get from the algorithm and use it to make decisions about whether or not they can rely on it.
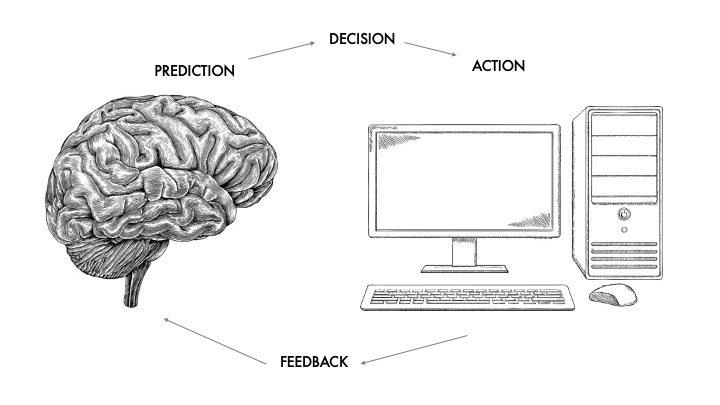 Mental models are sticky — once a user has a general idea of how the algorithm works, it’s really hard to convince them otherwise. The only way to make sure they’re getting it correct is by making sure the feedback — the answers — they’re getting are correct. So an algorithm’s outputs will exist in this answer space, and your users begin to develop a model of what are likely outputs given certain inputs. They’ll trust it more when it’s predictable, when they develop an understanding of how input A will turn into output Z.
Mental models are sticky — once a user has a general idea of how the algorithm works, it’s really hard to convince them otherwise. The only way to make sure they’re getting it correct is by making sure the feedback — the answers — they’re getting are correct. So an algorithm’s outputs will exist in this answer space, and your users begin to develop a model of what are likely outputs given certain inputs. They’ll trust it more when it’s predictable, when they develop an understanding of how input A will turn into output Z.
A really familiar example of this is music recommendations.
 In Spotfiy, Apple Music, whatever — all these platforms have automated “discovery” features. And we have a really intuitive sense of how they work — you listen to a lot of music of one genre or artist, and it will recommend you similar things. The algorithm is providing us feedback via its output about how the things we put in (what we listen to)…
In Spotfiy, Apple Music, whatever — all these platforms have automated “discovery” features. And we have a really intuitive sense of how they work — you listen to a lot of music of one genre or artist, and it will recommend you similar things. The algorithm is providing us feedback via its output about how the things we put in (what we listen to)…
 …to generate the output (what it recommends).
…to generate the output (what it recommends).
 This is wonderful and very predictable. People like this algorithm because it gives them interesting things and makes their lives easier. Ask anybody on the street how this works, and they can at least tell you how their inputs — the music they listen to — gets transformed into outputs.
This is wonderful and very predictable. People like this algorithm because it gives them interesting things and makes their lives easier. Ask anybody on the street how this works, and they can at least tell you how their inputs — the music they listen to — gets transformed into outputs.
 But what if you want it to recommend you something different, a little more ✨out there✨? The intuitive answer is that you should start listening to a lot of very different music,
But what if you want it to recommend you something different, a little more ✨out there✨? The intuitive answer is that you should start listening to a lot of very different music,
 But that might not work — we don’t really know what’s going on behind the scenes. We just have to trust our gut instinct about it and hope it works.
But that might not work — we don’t really know what’s going on behind the scenes. We just have to trust our gut instinct about it and hope it works.
 Aleister would be very proud. By showing users what’s going on — giving people some insight into the rules, even if you don’t give them control over them — you can help them leverage that algorithm even more.
Aleister would be very proud. By showing users what’s going on — giving people some insight into the rules, even if you don’t give them control over them — you can help them leverage that algorithm even more.
 Maybe it turns out that it’s not listening to different genres a lot in one sitting that triggers the algorithm to recommend me new stuff. Maybe it’s changing the frequency — listening to it more times over the week, regardless of how long I do it. Maybe it’s how often I skip tracks. Who knows! Wouldn’t it be nice if there was a way to find out?
Maybe it turns out that it’s not listening to different genres a lot in one sitting that triggers the algorithm to recommend me new stuff. Maybe it’s changing the frequency — listening to it more times over the week, regardless of how long I do it. Maybe it’s how often I skip tracks. Who knows! Wouldn’t it be nice if there was a way to find out?
 And this is what I mean about revealing the right complexities. The user doesn’t need to know that the similarity matrix of two users can be used to generate an eigenvalue of confidence that the recommendations are relevant. All they want to know is what they have to do to get the kind of recommendations they want. If what we’re trying to do is generate an answer space for our users, they’ll naturally use feedback to do that.
And this is what I mean about revealing the right complexities. The user doesn’t need to know that the similarity matrix of two users can be used to generate an eigenvalue of confidence that the recommendations are relevant. All they want to know is what they have to do to get the kind of recommendations they want. If what we’re trying to do is generate an answer space for our users, they’ll naturally use feedback to do that.
But we can speed that up by explaining to them what the algorithm is doing.
 Because at their core, algorithms are tools — remember that, because we’re going to come back to it — and nobody wants to use a tool they don’t understand.
Because at their core, algorithms are tools — remember that, because we’re going to come back to it — and nobody wants to use a tool they don’t understand.
 I think Bret Victor has a really nice way of approaching this. He has this concept of “explorable explanations” where you can enter in information and — in real time — see what the output is going to be. This is so simple! But it is immensely powerful, and you can use this with your algorithms. Think of it like allowing the user to run tiny simulations about things. The user can modify the inputs and immediately see how the algorithm will understand that.
I think Bret Victor has a really nice way of approaching this. He has this concept of “explorable explanations” where you can enter in information and — in real time — see what the output is going to be. This is so simple! But it is immensely powerful, and you can use this with your algorithms. Think of it like allowing the user to run tiny simulations about things. The user can modify the inputs and immediately see how the algorithm will understand that.
 I work in hearts, so let me give you an example there. So a key part of what a pacemaker has to do is look at the patient’s ECG and make a determination: is this normal and can I ignore it? Or is it dangerous, and should I do something about it?
I work in hearts, so let me give you an example there. So a key part of what a pacemaker has to do is look at the patient’s ECG and make a determination: is this normal and can I ignore it? Or is it dangerous, and should I do something about it?
 Now, you can give the user this list of parameters to adjust to help it with that detection. Tell the algorithm where and how to look for those dangerous arrhythmias. But even though this gives you control over the algorithm, it gives you no insight. It’s really hard to make smart decisions without insight.
Now, you can give the user this list of parameters to adjust to help it with that detection. Tell the algorithm where and how to look for those dangerous arrhythmias. But even though this gives you control over the algorithm, it gives you no insight. It’s really hard to make smart decisions without insight.
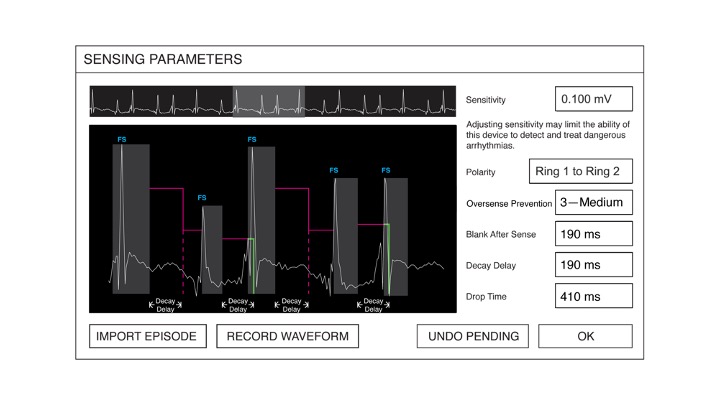 So we built this system that allows the user to see how the pacemaker is going to interpret signals from the heart. The algorithm is those pink lines there. Every time there’s a spike, there’s a period where the system isn’t detecting anything. That’s those grey boxes. By adjusting the parameters on the right, you could adjust the algorithm on the overlay and in real-time see how the device would interpret the signals. This was really important, because this was a brand-new algorithm for a brand-new class of devices. Nobody really knew how these worked, so we created this so they could experiment with them and feel confident that they weren’t going to kill their patient.
So we built this system that allows the user to see how the pacemaker is going to interpret signals from the heart. The algorithm is those pink lines there. Every time there’s a spike, there’s a period where the system isn’t detecting anything. That’s those grey boxes. By adjusting the parameters on the right, you could adjust the algorithm on the overlay and in real-time see how the device would interpret the signals. This was really important, because this was a brand-new algorithm for a brand-new class of devices. Nobody really knew how these worked, so we created this so they could experiment with them and feel confident that they weren’t going to kill their patient.
 These are the exact same controls, but now you can immediately understand how your decisions will impact the system. We didn’t modify anything about how the algorithm works — all we did was show how it works.
These are the exact same controls, but now you can immediately understand how your decisions will impact the system. We didn’t modify anything about how the algorithm works — all we did was show how it works.
 Aleister hates that.
Aleister hates that.
 So now you may be wondering — “What level of complexity should I reveal?” Well, only you can know that. You need to understand what it is that your users are trying to do with this tool that the algorithm is a part of, what they need to do that job well, and what’s going to get in their way. So go out and find out! Do your user research on this, and test what you built!
So now you may be wondering — “What level of complexity should I reveal?” Well, only you can know that. You need to understand what it is that your users are trying to do with this tool that the algorithm is a part of, what they need to do that job well, and what’s going to get in their way. So go out and find out! Do your user research on this, and test what you built!
 In this case, we learned that users were trying to get those FS markers to appear every time, and only for the big spikes. What they didn’t want to happen was have a bunch of noise come through and get interpreted as something dangerous. The “IMPORT EPISODE” button down there let them bring in noise to test it out and see if their settings worked for these spikes, but not for noise. So now we have feedback and these explorable explanations. Another really powerful way of explaining what an algorithm can do comes implicitly from the controls you reveal to your users.
In this case, we learned that users were trying to get those FS markers to appear every time, and only for the big spikes. What they didn’t want to happen was have a bunch of noise come through and get interpreted as something dangerous. The “IMPORT EPISODE” button down there let them bring in noise to test it out and see if their settings worked for these spikes, but not for noise. So now we have feedback and these explorable explanations. Another really powerful way of explaining what an algorithm can do comes implicitly from the controls you reveal to your users.
 Typically, you don’t want users to control the entire nuclear facility, but you also want them to do more than flick a switch. Most algorithms need to be adapted and given some control over how they work.
Typically, you don’t want users to control the entire nuclear facility, but you also want them to do more than flick a switch. Most algorithms need to be adapted and given some control over how they work.
 And it gets even more complex — because your users are likely to have a huge range of skill and knowledge levels. Some users might need more control and more access to the inner workings of an algorithm, but it’s probably bad to let a novice get in that deep.
And it gets even more complex — because your users are likely to have a huge range of skill and knowledge levels. Some users might need more control and more access to the inner workings of an algorithm, but it’s probably bad to let a novice get in that deep.
 The things you show and hide give the user an understanding of the space they have to operate in and what the algorithm will show them. These two steering wheels give you radically different insights into the vehicle. One lets you turn the car, the other lets you do quite a bit more. They give you immediate, implicit understanding of the complexity of what you’re working with. The parameters — the controls — you give someone access to so they can tweak an algorithm helps them understand what it does. Complex systems have more controls.
The things you show and hide give the user an understanding of the space they have to operate in and what the algorithm will show them. These two steering wheels give you radically different insights into the vehicle. One lets you turn the car, the other lets you do quite a bit more. They give you immediate, implicit understanding of the complexity of what you’re working with. The parameters — the controls — you give someone access to so they can tweak an algorithm helps them understand what it does. Complex systems have more controls.
 And you have to show some of those controls to your users so they understand what they can do.
And you have to show some of those controls to your users so they understand what they can do.
You ever been in a situation where you’re hanging out with your friends and they’re like “hey let’s play this game,” and already it’s overwhelming,
 and then they sit you down and the controller has like, WAY too many buttons, and you ask “so what am I supposed to do?”
and then they sit you down and the controller has like, WAY too many buttons, and you ask “so what am I supposed to do?”
 and they’re like — okay here are the controls, just try to fight us, and you’re like “ooooohkaaaaay,”
and they’re like — okay here are the controls, just try to fight us, and you’re like “ooooohkaaaaay,”
 and then you start playing, and they just absolutely kick your ass because they know everything about it and you don’t?
and then you start playing, and they just absolutely kick your ass because they know everything about it and you don’t?
 That’s because your space is way, way too big to operate in. But if you have a few handles on what you can do and what the goal is…
That’s because your space is way, way too big to operate in. But if you have a few handles on what you can do and what the goal is…
 …Well all of a sudden you feel a lot better about things. Exposing controls to the user gives them critical clues about what the algorithm is doing behind the scenes and how they can influence it.
…Well all of a sudden you feel a lot better about things. Exposing controls to the user gives them critical clues about what the algorithm is doing behind the scenes and how they can influence it.
 I mentioned dangerous arrhythmias before — let’s dig a little deeper. See, most pacemakers have leads in two chambers of the heart.
The atria up here suck in blood and push it down into the ventricles, which then push it out to the rest of the body.
I mentioned dangerous arrhythmias before — let’s dig a little deeper. See, most pacemakers have leads in two chambers of the heart.
The atria up here suck in blood and push it down into the ventricles, which then push it out to the rest of the body.
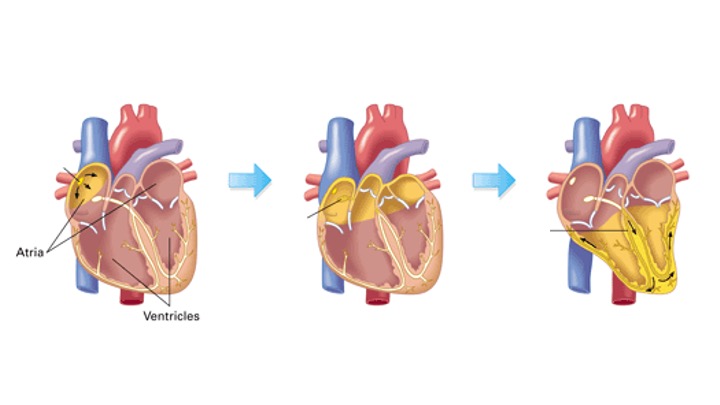 That suck-push sequence is very precisely timed — that lub-dub you feel in your heartbeat is your atria contracting, then your ventricles contracting. Turns out that if you get that sequence wrong — you contract the ventricle too fast after the atrium for example — people’s health really degrades. So it’s very important to get that timing bang on. A very common issue is called AV block — basically, the atria will beat and the ventricles will beat, they just don’t do it at the same time. To fix this, you put a lead in the atrium that listens for the beat, and then a lead in the ventricle that paces that chamber. So the atrium contracts, and the pacemaker forces the ventricle to contract.
That suck-push sequence is very precisely timed — that lub-dub you feel in your heartbeat is your atria contracting, then your ventricles contracting. Turns out that if you get that sequence wrong — you contract the ventricle too fast after the atrium for example — people’s health really degrades. So it’s very important to get that timing bang on. A very common issue is called AV block — basically, the atria will beat and the ventricles will beat, they just don’t do it at the same time. To fix this, you put a lead in the atrium that listens for the beat, and then a lead in the ventricle that paces that chamber. So the atrium contracts, and the pacemaker forces the ventricle to contract.
 This works really well! But hearts can be really unpredictable — and sometimes the atrium will beat in a dangerous way, like way too quickly. This is called tachycarida — and sometimes fibrillation. In the atrium it’s bad. But in the ventricle, it’s fatal within minutes.
This works really well! But hearts can be really unpredictable — and sometimes the atrium will beat in a dangerous way, like way too quickly. This is called tachycarida — and sometimes fibrillation. In the atrium it’s bad. But in the ventricle, it’s fatal within minutes.
 So if our pacemaker is listening to the atrium and pacing the ventricle at the same time, we have a problem if the atrium starts fibrillating.
So if our pacemaker is listening to the atrium and pacing the ventricle at the same time, we have a problem if the atrium starts fibrillating.
 The pacemaker will happily beat the ventricle every time the atrium does — including sending those fibrillations down to the ventricle.
Boom, you have a dead patient.
The pacemaker will happily beat the ventricle every time the atrium does — including sending those fibrillations down to the ventricle.
Boom, you have a dead patient.
So pacemakers have a lot of very complex algorithms in them that are used to respond correctly to those dangerous arrhythmias. And they work pretty well out of the box, but everyone is different, so we need to give control over them to our users. Some patients need very little intervention, and some patients are really complex and require a lot of tweaking. And some of our users are experts with decades of experience working with these devices, and others are total novices.
What do we do?
 Well, the thing we don’t do is expose everything, even if our power users constantly ask for it. Instead, we basically make it hard to get to the complex stuff that only a few people need and really easy to get to the stuff that most people need all the time.
Well, the thing we don’t do is expose everything, even if our power users constantly ask for it. Instead, we basically make it hard to get to the complex stuff that only a few people need and really easy to get to the stuff that most people need all the time.
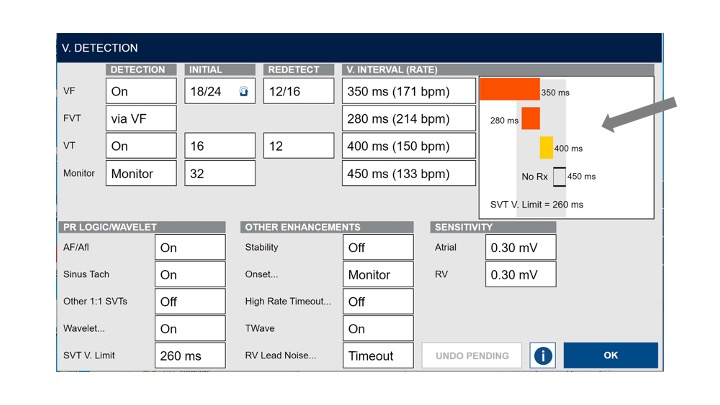 A lot of our users only ever need to adjust these rate bands. And hey, look at that! These are a great example of explorable explanations! Let’s walk through this screen a little bit.
A lot of our users only ever need to adjust these rate bands. And hey, look at that! These are a great example of explorable explanations! Let’s walk through this screen a little bit.
 The key metric here is the heart rate — generally the faster the rate, the worse off our patient is. But a really, really fast heart has different treatment needs than a slower one, so we give our users three different ways of managing them. A moderately fast heart — that’s ventricular tachycardia, or VT — is controlled from here. A little faster, that’s Fast VT. A very fast heart — ventricular fibrillation, VF — that’s here. They’re color-coded and you can see how they all line up. You can see what rates are going to be covered and if there are any gaps. And if you adjust anything, it gets updated here too.
The key metric here is the heart rate — generally the faster the rate, the worse off our patient is. But a really, really fast heart has different treatment needs than a slower one, so we give our users three different ways of managing them. A moderately fast heart — that’s ventricular tachycardia, or VT — is controlled from here. A little faster, that’s Fast VT. A very fast heart — ventricular fibrillation, VF — that’s here. They’re color-coded and you can see how they all line up. You can see what rates are going to be covered and if there are any gaps. And if you adjust anything, it gets updated here too.
For most people, this is enough! This gives them just enough information about the algorithm to understand how it’s going to respond to different rates, and enough control to adjust it to suit their patient’s needs. And we did it all with just a little graph! Now our users don’t have to just faith that their patients will get the right treatments at the right time, they can actually see it happening. These controls help demonstrate the space that a user can work in.
 Aleister would not like this at all.
Aleister would not like this at all.
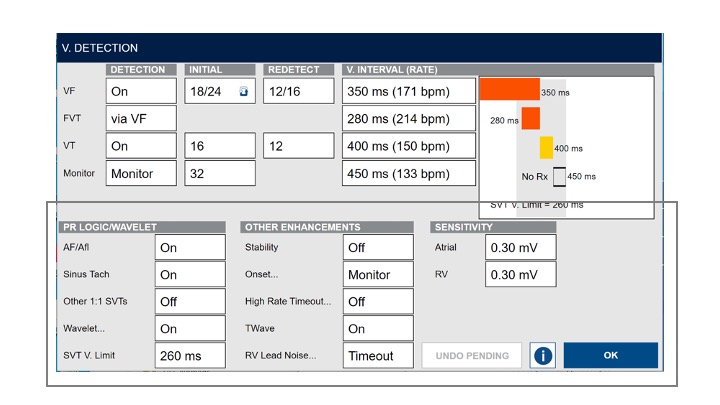 But some users need more control and have the knowledge to go with it. So we give them the option, but we make them go digging for it. If you click down here, you can see all the things you can do with the algorithm. It gives a lot more control, and expands the possibility space. The idea here is to give progressively more options to users who are looking for them, and protect the ones who aren’t from accidentally doing something dangerous.
But some users need more control and have the knowledge to go with it. So we give them the option, but we make them go digging for it. If you click down here, you can see all the things you can do with the algorithm. It gives a lot more control, and expands the possibility space. The idea here is to give progressively more options to users who are looking for them, and protect the ones who aren’t from accidentally doing something dangerous.
 This progressive complexity is really handy because it matches our users’ own experiences. When they start out, they don’t know anything and will consistently struggle with light switches.
This progressive complexity is really handy because it matches our users’ own experiences. When they start out, they don’t know anything and will consistently struggle with light switches.
 But as they get more experienced, they need that extra control, and when they go and look for it, we give it to them. Our users trust our system because it works consistently. The feedback they see is that dangerous things are not happening, and efficacy of care is. They have enough levers to pull that they can control the system to the level they need, based on their patient and their own knowledge. And they can see how changes they make will impact their patients in advance.
But as they get more experienced, they need that extra control, and when they go and look for it, we give it to them. Our users trust our system because it works consistently. The feedback they see is that dangerous things are not happening, and efficacy of care is. They have enough levers to pull that they can control the system to the level they need, based on their patient and their own knowledge. And they can see how changes they make will impact their patients in advance.
 What we’ve done here is more than just build trust in an algorithm, we’ve actually made our users better at their jobs. The UI — and the algorithm behind it — have enhanced their capability. And this is really important, because we’re not just building trust that an algorithm works. We also have to build trust that it’s a good thing.
What we’ve done here is more than just build trust in an algorithm, we’ve actually made our users better at their jobs. The UI — and the algorithm behind it — have enhanced their capability. And this is really important, because we’re not just building trust that an algorithm works. We also have to build trust that it’s a good thing.
 All this talk about LLMs has a lot of people worried about what’s going to happen to their jobs. And rightfully so! Maybe it’ll be a good thing, or maybe we’ll ask everyone to take things on faith and wind up inventing a weird cult and letting all our buddies die on a mountaintop.
All this talk about LLMs has a lot of people worried about what’s going to happen to their jobs. And rightfully so! Maybe it’ll be a good thing, or maybe we’ll ask everyone to take things on faith and wind up inventing a weird cult and letting all our buddies die on a mountaintop.
 (Grimacing hard) Yeesh.
(Grimacing hard) Yeesh.
 I would like to propose a theory of whether or not LLMs are a good thing that we can also apply to algorithms.
I would like to propose a theory of whether or not LLMs are a good thing that we can also apply to algorithms.
 So for pretty much all of modern human history, if you wanted a sign, someone had to write it. Either you did it yourself or you paid someone to do it. You’d put it over the door to your tavern, maybe, or you’d have someone paint on the inside of your window so they know what you sold inside.
So for pretty much all of modern human history, if you wanted a sign, someone had to write it. Either you did it yourself or you paid someone to do it. You’d put it over the door to your tavern, maybe, or you’d have someone paint on the inside of your window so they know what you sold inside.
 Signpainting really took off at the turn of the 19th century. Hand-painted signs were everywhere doing all sorts of jobs. It was a huge industry! And it died a sudden and rapid death thanks —
Signpainting really took off at the turn of the 19th century. Hand-painted signs were everywhere doing all sorts of jobs. It was a huge industry! And it died a sudden and rapid death thanks —
 to this —
to this —
 And this.
And this.
In the 90’s and 2000’s, suddenly you didn’t need to pay someone to paint a sign for you. You could type it up yourself on a computer, print it off, and stick it up there. When was the last time you hired a sign painter? Sure, maybe these desktop printoffs didn’t look as nice, but that didn’t really matter. They communicated the required information, and they did it basically for free. They weren’t perfect, but they were good enough.
 LLMs and (shudder) “AI” are the new desktop publishing platforms. They’re going to replace the things that we don’t need something incredible for. The “good enough” stuff. Here’s a concrete example —
LLMs and (shudder) “AI” are the new desktop publishing platforms. They’re going to replace the things that we don’t need something incredible for. The “good enough” stuff. Here’s a concrete example —
 This image from my cover slide is AI-generated. I wanted a picture, and the AI did a good enough job.
This image from my cover slide is AI-generated. I wanted a picture, and the AI did a good enough job.
 This one was too.
This one was too.
 And this one too!
And this one too!
 Here’s the thing about them — they’re just good enough. If I didn’t have a AI tool to make them, I just would have gone on Google and found something similar.
Here’s the thing about them — they’re just good enough. If I didn’t have a AI tool to make them, I just would have gone on Google and found something similar.
 If I want a painting that excites me,
If I want a painting that excites me,
 if I want a book that gets me thinking,
if I want a book that gets me thinking,
 if i want a movie that moves me — I’m going to rely on a human for that. But if I need to bang out a boilerplate email to someone and an LLM can do that? Hell yeah, that’s good enough for me.
if i want a movie that moves me — I’m going to rely on a human for that. But if I need to bang out a boilerplate email to someone and an LLM can do that? Hell yeah, that’s good enough for me.
 It saves me time. It saves me effort. It becomes an enhancement for me. It’s like any other good tool: it becomes a part of how i think about and solve problems. And that’s what your algorithms should be doing too. They should be enhancing your users, not replacing them.
It saves me time. It saves me effort. It becomes an enhancement for me. It’s like any other good tool: it becomes a part of how i think about and solve problems. And that’s what your algorithms should be doing too. They should be enhancing your users, not replacing them.
 This idea comes from Doug Engelbart, an absolute titan in the field of human-computer interaction.
This idea comes from Doug Engelbart, an absolute titan in the field of human-computer interaction.
 He invented the mouse,
He invented the mouse,
 the word processor,
the word processor,
 hypertext,
hypertext,
 networked computers — aka the internet —
networked computers — aka the internet —
 the graphical user interface, and he did it basically all in one presentation. Now it’s called the “Mother of all Demos.” Go look it up — it’s one of those things that’s almost not impressive anymore because everything he shows is so common now. But he was doing it sixty years ago!
the graphical user interface, and he did it basically all in one presentation. Now it’s called the “Mother of all Demos.” Go look it up — it’s one of those things that’s almost not impressive anymore because everything he shows is so common now. But he was doing it sixty years ago!
 So he had this idea of augmented intelligence. If we think of tools as augments to what we can already do — a hammer lets me swing with more force and precision than my hand allows — then a computer should be a tool that augments our intelligence. We should be able to think better, filter more data, make more informed decisions — the computer should be supporting that by doing all the boring scut work we normally have to do.
So he had this idea of augmented intelligence. If we think of tools as augments to what we can already do — a hammer lets me swing with more force and precision than my hand allows — then a computer should be a tool that augments our intelligence. We should be able to think better, filter more data, make more informed decisions — the computer should be supporting that by doing all the boring scut work we normally have to do.
 If it can do a good enough job on its own, we can replace a lot of the boring stuff with an algorithm.
If it can do a good enough job on its own, we can replace a lot of the boring stuff with an algorithm.
 That’s how you build an algorithm. To save your users time and energy. Now they don’t have to learn linear algebra to get infinite music recommendations. Now they don’t have to be experts on cardiac electrophysiology to stop someone from dying. You’ve taken a hard part of their job and made it easier, and in doing so you’ve freed up their time to do more complex things, more interesting things, the same jobs but better.
That’s how you build an algorithm. To save your users time and energy. Now they don’t have to learn linear algebra to get infinite music recommendations. Now they don’t have to be experts on cardiac electrophysiology to stop someone from dying. You’ve taken a hard part of their job and made it easier, and in doing so you’ve freed up their time to do more complex things, more interesting things, the same jobs but better.
And this is how you explain it. This is how you build it. Algorithms aren’t coming for your paycheck, they’re coming for your podcasts. Now all the time you used to spend listening to them while you did mindless things for your job are replaced by a computer and you get to focus on the interesting stuff.
 If there’s one other thing I want you to remember from this talk besides Crowley,
If there’s one other thing I want you to remember from this talk besides Crowley,
 it’s this: an algorithm is an enhancement, not a replacement, for a person. And you should be building your interfaces with that in mind.
it’s this: an algorithm is an enhancement, not a replacement, for a person. And you should be building your interfaces with that in mind.
 We make this palatable to users through developing trust, not faith. Don’t preach about how this algorithm is going to save them time, show them. Show them every time they interact with the system by revealing the right things to them, giving them the right level of control, by letting them see how A turns into Z. Don’t make them crack open the Book of Thoth every time they want answers for how the system works.
We make this palatable to users through developing trust, not faith. Don’t preach about how this algorithm is going to save them time, show them. Show them every time they interact with the system by revealing the right things to them, giving them the right level of control, by letting them see how A turns into Z. Don’t make them crack open the Book of Thoth every time they want answers for how the system works.
 Think about how angry Aleister is going to be when the answers are already provided for them! So I hope I’ve demonstrated why trust is so essential. Because sometimes the algorithm is going to give you an output you didn’t expect, and it’s going to be right. And in that moment, your user is going to have to trust it, because it might be a life- or-death decision.
Think about how angry Aleister is going to be when the answers are already provided for them! So I hope I’ve demonstrated why trust is so essential. Because sometimes the algorithm is going to give you an output you didn’t expect, and it’s going to be right. And in that moment, your user is going to have to trust it, because it might be a life- or-death decision.
 Despite our best abilities, things will go wrong. An algorithm will make a bad call. Someone will enter bad data and get bad data back. Your job as a designer is twofold: it’s to identify what the errors are and make them easy for your usrs to idetnfiy.
Despite our best abilities, things will go wrong. An algorithm will make a bad call. Someone will enter bad data and get bad data back. Your job as a designer is twofold: it’s to identify what the errors are and make them easy for your usrs to idetnfiy.
 It’s to minimize the likelihood bad things happen, and to make them easy to fix when they do. With an algorithm, this can be surprisingly challenging.
It’s to minimize the likelihood bad things happen, and to make them easy to fix when they do. With an algorithm, this can be surprisingly challenging.
 The first thing you have to do is come up with a definition: what even counts as an error here?
The first thing you have to do is come up with a definition: what even counts as an error here?
 We have to remember that we’re not defining human errors here. Algorithms don’t make mistakes and they don’t have slips. An error in this case is where there is a difference between
We have to remember that we’re not defining human errors here. Algorithms don’t make mistakes and they don’t have slips. An error in this case is where there is a difference between
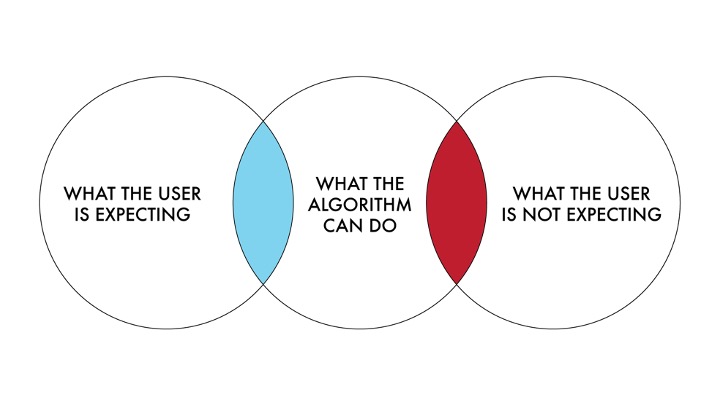 what the user is expecting the algorithm to provide and what the system actually provided. And let’s be really clear about this for a second — there is a difference between an error and an unexpected result.
what the user is expecting the algorithm to provide and what the system actually provided. And let’s be really clear about this for a second — there is a difference between an error and an unexpected result.
 Unexpected results are surprises! (Internally count to seven, wait for scattered laughter)
Unexpected results are surprises! (Internally count to seven, wait for scattered laughter)
 Because just because the algorithm did something you didn’t expect doesn’t mean it was wrong. You have to define what counts as incorrect. And usually, algorithmic errors fall into two categories:
Because just because the algorithm did something you didn’t expect doesn’t mean it was wrong. You have to define what counts as incorrect. And usually, algorithmic errors fall into two categories:
 false negatives and false positives. There are certainly more errors that can happen, but this is a nice framework generally.
false negatives and false positives. There are certainly more errors that can happen, but this is a nice framework generally.
 A false negative is when the system doesn’t do something it was supposed to, and a false positive is when it does something it shouldn’t have.
A false negative is when the system doesn’t do something it was supposed to, and a false positive is when it does something it shouldn’t have.
 And the really tricky part here is that by definition, the system can’t tell that an error happened — if it did, then it could have prevented it. The only way that an error can be identified is if a human notices — and if the data is available.
And the really tricky part here is that by definition, the system can’t tell that an error happened — if it did, then it could have prevented it. The only way that an error can be identified is if a human notices — and if the data is available.
 Which is why algorithms are tools that enhance, not replace, and we build systems we can understand.
Which is why algorithms are tools that enhance, not replace, and we build systems we can understand.
 Okay, so you got your surprising result. Now it needs to be checked to make sure an error didn’t occur. Someone has to sit down and diagnose the output.
Okay, so you got your surprising result. Now it needs to be checked to make sure an error didn’t occur. Someone has to sit down and diagnose the output.
 The first thing you have to do is alert the user that an error even happened. This is not always easy — sometimes an algorithm knows when it didn’t work. Maybe the input data was bad or outside a range it could work with. If the algorithm can tell something went wrong, tell the user and give them some advice. This is basic error handling stuff I won’t get into here.
The first thing you have to do is alert the user that an error even happened. This is not always easy — sometimes an algorithm knows when it didn’t work. Maybe the input data was bad or outside a range it could work with. If the algorithm can tell something went wrong, tell the user and give them some advice. This is basic error handling stuff I won’t get into here.
 What’s much trickier is when the system made a mistake and it can’t tell. The only way to know something went wrong is to provide a backup to the user — and have someone looking for it. You have to present all the outputs of an algorithm to the user, which usually means they need some tools to sort through the outputs to get what they’re looking for. Most of the time the algorithm does this for you — but when something unexpected happens, you need to pop the hood and get in there yourself to take a look.
What’s much trickier is when the system made a mistake and it can’t tell. The only way to know something went wrong is to provide a backup to the user — and have someone looking for it. You have to present all the outputs of an algorithm to the user, which usually means they need some tools to sort through the outputs to get what they’re looking for. Most of the time the algorithm does this for you — but when something unexpected happens, you need to pop the hood and get in there yourself to take a look.
 Back in heart-world, we keep track of every time the device detects what it thinks is a dangerous heartbeat. It stores the information about what the heart did, how it classified it, and what happened during the event. This information is always available, and the user has ways of searching through it to get what they need.
Back in heart-world, we keep track of every time the device detects what it thinks is a dangerous heartbeat. It stores the information about what the heart did, how it classified it, and what happened during the event. This information is always available, and the user has ways of searching through it to get what they need.
 In this case, our users are curious about what happened since they last saw this patient,
In this case, our users are curious about what happened since they last saw this patient,
 which arrhythmias had shocks,
which arrhythmias had shocks,
 and the specific kinds of rhythms that this patient commonly has. The rest is important, so we still show it, but we don’t put it front and center. This UI is built around giving the user the tools they need to understand the algorithm.
and the specific kinds of rhythms that this patient commonly has. The rest is important, so we still show it, but we don’t put it front and center. This UI is built around giving the user the tools they need to understand the algorithm.
 It can be really tempting to just discard the things we don’t really care about. If the point of an algorithm is to save the user’s time, we shouldn’t give them the option to examine what we discarded, right?
It can be really tempting to just discard the things we don’t really care about. If the point of an algorithm is to save the user’s time, we shouldn’t give them the option to examine what we discarded, right?
 That’s a very Aleister way of thinking. If you have a 1% failure rate, 99% of the time your users never have to dig through the trash. But in that 1% of cases, it’s vitally important so users can understand what went wrong.
That’s a very Aleister way of thinking. If you have a 1% failure rate, 99% of the time your users never have to dig through the trash. But in that 1% of cases, it’s vitally important so users can understand what went wrong.
 Usually what you need to show them is: how the algorithm reached its decision, and what it did with what it analyzed. This allows your users to check that everything worked the way it was supposed to and confirm that there’s nothing inappropriately ignored.
Usually what you need to show them is: how the algorithm reached its decision, and what it did with what it analyzed. This allows your users to check that everything worked the way it was supposed to and confirm that there’s nothing inappropriately ignored.
 Remember, you don’t want to be a black box. So a huge amount of building trust is not getting rid of stuff and making it easy for your users to understand what’s going on. It’s important that users are aware of not only when things work, but also when things go wrong. It’s important when building an answer space to be aware of what the wrong answers are just as much as you know about the right ones. Black boxes lead to faith, not trust. Black boxes lead to
Remember, you don’t want to be a black box. So a huge amount of building trust is not getting rid of stuff and making it easy for your users to understand what’s going on. It’s important that users are aware of not only when things work, but also when things go wrong. It’s important when building an answer space to be aware of what the wrong answers are just as much as you know about the right ones. Black boxes lead to faith, not trust. Black boxes lead to
 you founding a new religion that kills a guy while his wife drinks animal blood
you founding a new religion that kills a guy while his wife drinks animal blood
 Or you getting sued and not being able to defend yourself effectively.
Or you getting sued and not being able to defend yourself effectively.
 Keeping a human in the loop is important for another, slightly darker reason: it gives you someone to blame when things go wrong. Let’s talk about the trolley problem.
Keeping a human in the loop is important for another, slightly darker reason: it gives you someone to blame when things go wrong. Let’s talk about the trolley problem.
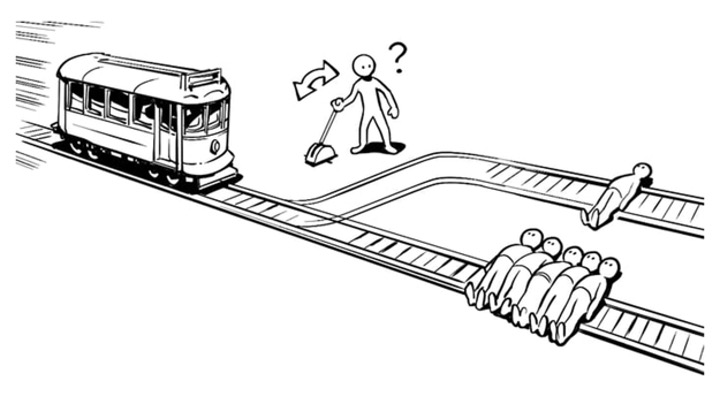 You probably already know about it — imagine you’re a bystander and a trolley is on the tracks ahead of you. It’s running down the tracks and about to hit a big group of people, but you can pull the switch so it hits one person instead. Do you do it? (Pause for moral reflection.)
You probably already know about it — imagine you’re a bystander and a trolley is on the tracks ahead of you. It’s running down the tracks and about to hit a big group of people, but you can pull the switch so it hits one person instead. Do you do it? (Pause for moral reflection.)
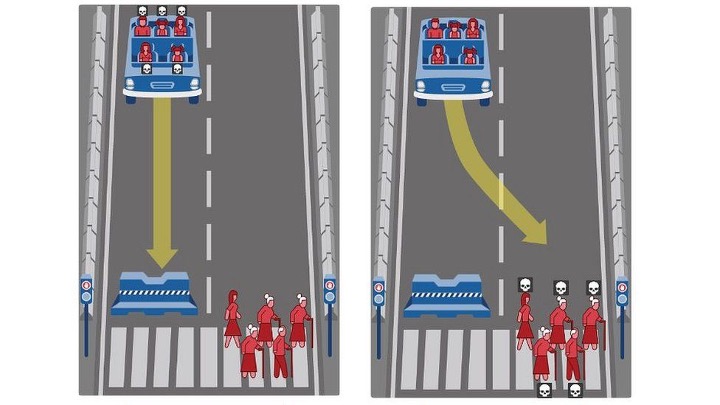 Let’s take this and apply it to self-driving cars. The car is in a situation where it’s about to hit a wall at high speed — fast enough that the driver is certain to die when it happens. But it could swerve out of the way and barrel into a crowd of people crossing the street instead. This would kill and maim them, but the driver would survive. What should it do? What should it be programmed to do? And when a self-driving car is involved in an inevitable fatal accident, who’s liable for it? Is it the car company? The person who trusted the car not to kill them?
Let’s take this and apply it to self-driving cars. The car is in a situation where it’s about to hit a wall at high speed — fast enough that the driver is certain to die when it happens. But it could swerve out of the way and barrel into a crowd of people crossing the street instead. This would kill and maim them, but the driver would survive. What should it do? What should it be programmed to do? And when a self-driving car is involved in an inevitable fatal accident, who’s liable for it? Is it the car company? The person who trusted the car not to kill them?
 Is it the person who designed the algorithm? (Pause for existential panic.) Now, I am not a lawyer or a philosopher, but I think we can all tell that this is murky ground with no good, easy answers.
Is it the person who designed the algorithm? (Pause for existential panic.) Now, I am not a lawyer or a philosopher, but I think we can all tell that this is murky ground with no good, easy answers.
 And there really aren’t any answers out there right now. There have been a few cases with self-driving cars killing people, but those weren’t truly autonomous — they had someone sitting in the driver’s seat who was supposed to take over. There was a human to blame —
And there really aren’t any answers out there right now. There have been a few cases with self-driving cars killing people, but those weren’t truly autonomous — they had someone sitting in the driver’s seat who was supposed to take over. There was a human to blame —
 and guess what, that human got blamed and went to prison for it.
and guess what, that human got blamed and went to prison for it.
 When it comes to medtech, we usually say the buck stops with the physician. We make all sorts of algorithmic recommendations and provide tons of feedback, but at the end of the day we absolve ourselves of guilt by requiring a doctor to sign off. That signature is a transfer of liability from us, the designers and company, to the doctor and their malpractice insurance.
When it comes to medtech, we usually say the buck stops with the physician. We make all sorts of algorithmic recommendations and provide tons of feedback, but at the end of the day we absolve ourselves of guilt by requiring a doctor to sign off. That signature is a transfer of liability from us, the designers and company, to the doctor and their malpractice insurance.
 There is this assumption that if we tell our users what the risks are, what percentage of false positives and negatives there are,
they make rational decisions and accept that risk to themselves. “Just a 5% false negative rate,” we say, and the physician is implicitly supposed to be comfortable with the idea. But how much of that information is really communicated, and how much is hidden away in tiny text? When was the last time you saw a system advertised that said ”with our algorithm, only a million people every year are falsely cleared from having cancer!” We, as human beings, are really bad at assessing risk and thinking about the consequences of it.
There is this assumption that if we tell our users what the risks are, what percentage of false positives and negatives there are,
they make rational decisions and accept that risk to themselves. “Just a 5% false negative rate,” we say, and the physician is implicitly supposed to be comfortable with the idea. But how much of that information is really communicated, and how much is hidden away in tiny text? When was the last time you saw a system advertised that said ”with our algorithm, only a million people every year are falsely cleared from having cancer!” We, as human beings, are really bad at assessing risk and thinking about the consequences of it.
 Right now there is basically no precedent for any of this. But surely the day is coming where a patient dies because an algorithm cleared them incorrectly.
Right now there is basically no precedent for any of this. But surely the day is coming where a patient dies because an algorithm cleared them incorrectly.
There will be court cases, with a physician blaming the system manufacturer and the company blaming the physician for not paying close enough attention. But where is the line? If you keep all the outputs the algorithm produced, is that better than deleting them? What if you have 1000 negative results, and just five of them are actually false negatives? Is it reasonable to ask your customers to have pored over that data themselves to find it?
 As algorithms become more common, we risk overloading our users with data that obscures the real risks to a patient. Algorithms are intending to help us sift signal from noise, but the ironic thing is that we may just be creating new noise to help us hedge our bets. We have a responsibility as designers to make sure that we’re not just giving users access to all the data, but to the right data. aAd we need to make sure that we help them have insights into not just what an algorithm is doing, but what it produced. We need to make sure they understand what a 5% risk is, what a 10% risk is. What does that mean for their patients? What does it mean for them?
As algorithms become more common, we risk overloading our users with data that obscures the real risks to a patient. Algorithms are intending to help us sift signal from noise, but the ironic thing is that we may just be creating new noise to help us hedge our bets. We have a responsibility as designers to make sure that we’re not just giving users access to all the data, but to the right data. aAd we need to make sure that we help them have insights into not just what an algorithm is doing, but what it produced. We need to make sure they understand what a 5% risk is, what a 10% risk is. What does that mean for their patients? What does it mean for them?
 Who wants to go to prison because an algorithm screwed up?
Who wants to go to prison because an algorithm screwed up?
 Surely people have been harmed, but I suspect that until now, it’s mostly been buried in a bunch of other medical and legal data that obscures the root cause.
Surely people have been harmed, but I suspect that until now, it’s mostly been buried in a bunch of other medical and legal data that obscures the root cause.
Right now, a lot of us are operating in a space where these aren’t concerns because the risks are seen as low. Errors “just don’t happen.” Or they aren’t a big deal. But i’d like to amend that.
 errors “just don’t happen — yet.” Mark my words, the day is coming where an algorithm is to blame for someone’s death, and when that happens, it will be a seismic shift in how we use them.
errors “just don’t happen — yet.” Mark my words, the day is coming where an algorithm is to blame for someone’s death, and when that happens, it will be a seismic shift in how we use them.
 Whew! That got heavy. So here’s what i want to leave you with today, four key things to think about when building interfaces for algorithms. Trust, not faith. No black boxes!
Whew! That got heavy. So here’s what i want to leave you with today, four key things to think about when building interfaces for algorithms. Trust, not faith. No black boxes!
 Show them how it works, and give them access to the levers that suit their need and their ability level.
Show them how it works, and give them access to the levers that suit their need and their ability level.
 Tell them about errors the system can notice and give them tools to look into surprising results.
Tell them about errors the system can notice and give them tools to look into surprising results.
 And don’t be Aleister Crowley!
And don’t be Aleister Crowley!
Thank you all for coming and listening so intently on this beautiful summer day.